RAG(Retrieval-Augmented Generation) 시스템을 도입하는 조직이 늘고 있습니다. 특히 지방자치단체나 공공기관처럼 내부 문서가 방대하고, 질의응답 정확도에 법적·행정적 책임이 따르는 환경에서는 단순히 LLM 모델을 붙이는 것만으로는 충분하지 않습니다. 모델이 참조할 문서 데이터 자체가 잘 정제되어 있어야 합니다.
이 글은 실제 지자체 행정 문서를 대상으로 수행한 RAG 학습 데이터 구축 프로젝트의 작업 과정을 정리한 것입니다. 공공 도메인 특성상 데이터 정제 기준이 까다롭기 때문에, RAG 학습 데이터 구축 단계별 판단 기준을 중심으로 기술합니다.
왜 PDF를 그냥 넣으면 안 되는가
많은 RAG 구현 사례에서 초기에 가장 많이 범하는 실수가 있습니다. PDF를 별다른 전처리 없이 텍스트로 추출해 벡터DB에 넣는 것입니다.
PDF는 인쇄 목적으로 설계된 포맷입니다. 줄바꿈이 문장 중간에 들어가거나, 표가 셀 단위로 분리되거나, 페이지 번호·머리글·바닥글이 본문과 뒤섞입니다. OCR 기반 스캔 문서라면 특수문자 오인식이나 줄 순서 역전도 발생합니다. 이 상태의 텍스트를 그대로 청킹하면, 검색 시 의미가 단절된 조각이 반환되거나 노이즈 문장이 답변 생성에 개입하게 됩니다.
RAG 시스템의 품질은 결국 검색(Retrieval) 단계의 정확도에 달려 있고, 검색 정확도는 청크 품질에서 결정됩니다. 좋은 임베딩 모델이나 고성능 LLM도 입력 데이터가 지저분하면 한계가 있습니다.
이번 프로젝트에서 다룬 문서는 행정업무운영편람, 산업안전보건관리비 해설집, 공사계약 길라잡이 등 수백 페이지 분량의 PDF였습니다. 표, 이미지 캡션, 법령 조문, 사례 설명이 혼재된 구조였고, 단순 텍스트 추출만으로는 처리할 수 없는 요소들이 상당했습니다.
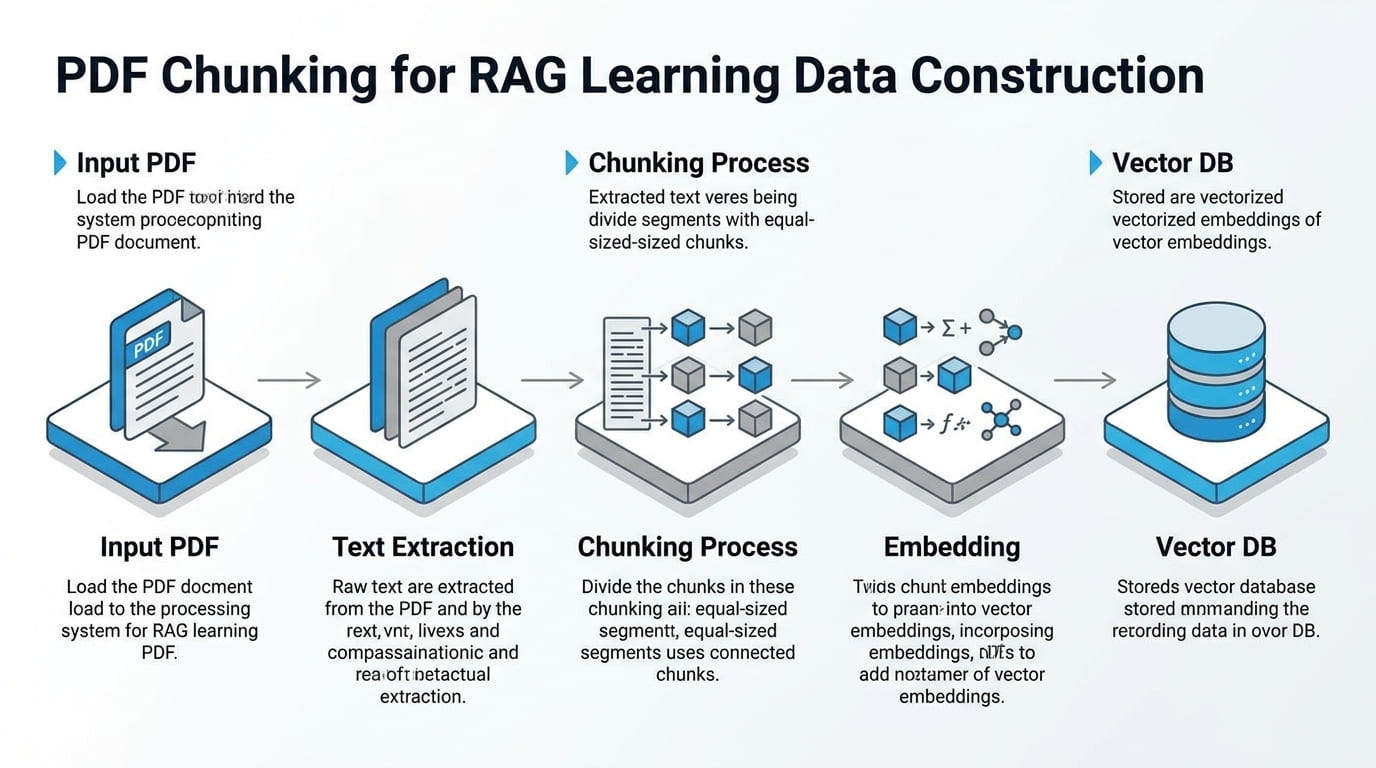
[1단계] PDF 파싱 및 텍스트 정제
작업의 첫 번째 과제는 PDF의 모든 정보를 손실 없이 텍스트로 변환하는 것입니다. 여기서 ‘손실 없이’라는 표현이 중요합니다. 텍스트 본문만이 아니라 표, 이미지, 차트에 담긴 정보까지 포함해야 합니다.
텍스트 본문 처리
PDF 파싱 후 발생하는 주요 오류 유형은 다음과 같습니다.
- 줄바꿈 오류: 한 문장이 여러 줄로 분리되어 추출됨
- 특수문자 혼입: 불릿 기호, 공백 문자, 제어 문자 등
- 레거시 문구: 구버전 문서에서 사용된 비표준 표현
- 페이지 아티팩트: 페이지 번호, 장 제목이 본문 문장 사이에 삽입됨
이를 문장 단위로 재구성하고, 의미 단위가 끊기지 않도록 수작업 검수를 병행했습니다. 자동화 파싱만으로는 해결되지 않는 예외 케이스가 반드시 존재합니다.
표·이미지·차트 처리
RAG에서 표를 그대로 넣으면 검색이 잘 되지 않습니다. 표는 열과 행의 관계로 의미가 구성되는데, 텍스트로 직렬화(serialization)하면 이 구조가 사라지기 때문입니다.
이번 프로젝트에서는 표의 각 행을 의미 단위로 분리해 자연어 서술로 변환했습니다. 예를 들어 ‘문서 종류 / 작성 형식 / 문서 번호’ 형태의 표는 “법규 문서 중 훈령·예규는 조문 형식 또는 시행문 형식을 사용하며 누년 일련번호를 부여한다”는 식으로 각 행을 독립된 청크로 풀어냈습니다.
이미지와 차트는 시각적 정보를 텍스트 설명으로 변환했습니다. UI 캡처 이미지라면 화면에서 보이는 버튼, 팝업 내용, 단계별 동작을 순서대로 서술하는 방식으로 처리했습니다. 이렇게 해야 “행정용어 순화어 검색 기능은 어떻게 사용하나요?”와 같은 질의에 대해 이미지 정보가 검색 결과로 반환될 수 있습니다.
[2단계] 청킹 설계와 메타데이터 구성
파싱이 끝난 텍스트를 어떻게 분할하고 어떤 메타데이터를 붙이느냐가 RAG 성능의 실질적인 분기점입니다.
청킹 단위 설계
청킹 방식에는 고정 길이 분할, 문단 단위 분할, 의미 단위 분할 등 여러 방법이 있습니다. 이번 프로젝트에서는 문서의 목차 구조를 기준으로 의미 단위 청킹을 적용했습니다.
행정 문서는 대부분 위계적 목차 구조(편 > 장 > 절 > 항)를 갖추고 있습니다. 이 구조를 활용하면 각 청크가 하나의 행정 개념 또는 규정 단위에 대응하게 됩니다. 검색 시 관련 청크가 정확하게 묶여서 반환되고, 무관한 내용이 섞이는 경우가 줄어듭니다.
메타데이터 설계
각 청크에는 아래 필드를 구성했습니다.
| 필드명 | 내용 |
|---|---|
| source | 문서명 |
| year | 발행연도 |
| page | PDF 페이지 번호 |
| section1 | 상위 목차 |
| section2 | 중간 목차 |
| section3 | 소분류 (있는 경우) |
| chunk_id | 문단 고유 번호 (예: p058_01) |
메타데이터가 중요한 이유는 검색 결과의 신뢰성 판단에 쓰이기 때문입니다. 같은 내용이라도 2018년 편람 기준인지 2024년 기준인지에 따라 답변의 유효성이 달라집니다. 출처와 연도 정보가 청크에 붙어 있으면 LLM이 답변 생성 시 이를 참조하거나 필터링 조건으로 활용할 수 있습니다.
chunk_id 체계는 페이지 번호와 순번을 조합해 설계했습니다. 나중에 원본 문서를 역추적하거나 오류 청크를 수정할 때 이 ID가 기준점이 됩니다. CSV 파일은 문서별로 1개씩 분리해 관리했습니다. 전체를 하나로 합치면 추후 문서 단위 업데이트나 버전 관리가 어려워집니다.
[3단계] Q&A 데이터셋 구성 (Positive / Negative)
청킹된 데이터는 AI 학습 데이터로 바로 활용할 수도 있지만, LLM 파인튜닝을 병행하는 경우에는 Q&A 형태의 데이터셋이 별도로 필요합니다. 이번 프로젝트에서는 Positive Sample과 Negative Sample을 모두 구성했습니다.
Positive Sample 답변 가능한 질문
Positive Sample은 문서에서 실제로 답변 가능한 질문과 답변 쌍입니다. 질문은 사용자가 실제로 할 법한 자연어 형태로 작성했습니다. “가. 민원행정의 특징”처럼 목차를 그대로 가져오는 방식은 지양했습니다. 사용자는 목차 언어로 질문하지 않기 때문입니다.
답변(output)은 핵심 내용을 명확하게 정리하되, 과도하게 축약하지 않았습니다. “4가지가 있습니다”로 끝내는 답변은 실제로 도움이 되지 않습니다. 각 항목의 핵심 키워드와 설명이 포함되어야 사용자가 추가 검색 없이 내용을 이해할 수 있습니다.
Q&A 수는 청크의 행 수를 기준으로 설계했습니다. section2 기준으로 1~2행이면 1개, 3~5행이면 2개, 6~10행이면 3개 등 점진적으로 늘리는 방식입니다. 내용이 많은 섹션에서 더 많은 질문을 뽑아내되, 억지로 늘리지는 않습니다.
각 샘플에는 메타 정보도 함께 구성했습니다.
- meta_category: 문서 도메인 분류 (예: 공통행정, 세무)
- meta_year: 문서 기준 연도
- meta_time_fixed: 시간 불변 규정 여부 (true/false)
- meta_reference: 출처 경로 (문서명 > 중제목 > 소제목)
- meta_confidence: 답변 신뢰도 (high / medium / low)
meta_time_fixed 필드가 실무적으로 유용합니다. 행정 문서는 법령 개정에 따라 수시로 내용이 바뀝니다. 불변 규정과 가변 규정을 구분해두면 추론 시 시간 의존성이 높은 질문에 대해 별도 처리를 적용할 수 있습니다.
Negative Sample 답변 불가 질문
Negative Sample은 모델이 “이 문서에 근거가 없으면 추론하지 말고 회피하라”는 행동을 학습하도록 설계합니다. 공공기관 LLM에서 특히 중요한 부분입니다. 잘못된 정보를 사실인 것처럼 답변하는 것은 단순한 오류가 아니라 행정적 혼선을 야기할 수 있습니다.
Negative Sample의 구성은 단순합니다. 문서에 근거가 없는 질문(예: “OO부서장 전화번호는?”, “최근 5년간 예산 집행률은?”)에 대해 input에 “내부 규정 미제공”을 명시하고, output은 “관련 정보가 없습니다”로 통일합니다. 이 패턴을 충분히 학습시키면 모델이 근거 없는 답변을 생성하는 빈도가 낮아집니다.
Negative Sample 수는 section2 기준으로 10행 이하이면 1개, 10행 초과이면 2개를 기본 설계로 했습니다.
데이터 품질을 결정하는 실질적 기준
AI 데이터 가공 관점에서 이 프로젝트의 핵심 판단 기준은 세 가지였습니다.
(RAG 데이터 품질 기준에 대한 학술적 배경은 Lewis et al.(2020) “Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks”에서도 확인하실 수 있습니다.)
첫째, 청크가 독립적으로 의미를 가지는가입니다. 앞뒤 청크를 참조하지 않아도 해당 청크만으로 질문에 답변할 수 있어야 합니다. 문맥 의존적인 청크는 검색 결과로 반환되어도 LLM이 올바른 답변을 생성하기 어렵습니다.
둘째, 표와 이미지가 검색 가능한 형태로 변환되었는가입니다. 시각 정보가 텍스트로 서술되지 않으면 해당 내용은 벡터DB에서 사실상 검색 불가 상태가 됩니다. 행정 문서에서 표가 차지하는 비중을 고려하면 이 부분을 건너뛰는 것은 데이터의 상당 부분을 버리는 것과 같습니다.
셋째, Negative Sample이 충분히 다양한가입니다. 답변 불가 질문의 유형이 단순 반복되면 모델이 특정 패턴만 학습하게 됩니다. 질문 유형(연락처, 예산, 인사 정보 등)을 다양하게 구성해야 실제 운영 환경에서 회피 행동이 일관되게 작동합니다.
마치며
RAG 시스템의 완성도는 모델 선택보다 데이터 설계에서 더 크게 갈립니다. RAG 학습 데이터 구축 과정에서 전처리와 청킹 설계에 충분한 시간을 투자하는 것이 결국 시스템 전체 품질을 결정합니다. PDF를 그대로 넣고 성능이 기대에 못 미친다고 판단하는 경우를 자주 봅니다. 대부분은 데이터 전처리 단계의 문제입니다.
이번 프로젝트를 통해 정리된 기준은 행정 문서 외에도 법령집, 기술 매뉴얼, 사내 규정집 등 구조화된 문서 기반 RAG에 동일하게 적용될 수 있습니다. 유사한 프로젝트를 계획 중이시라면 데이터 구조 설계 단계부터 충분한 시간을 배정하시길 권장합니다.